Java大厦的基石——Java Class文件构成
工欲善其事,必先利其器——编译&反编译Java代码
在我们平时的开发中,程序员所书写的文件叫做“源代码文件”,一般后缀是“.java”,源代码文件一般用贴近人类语言的表述方便我们的开发工作。
然而,源代码文件Java虚拟机是无法识别的,需要将源代码文件编译成字节码文件(.class文件),才能被Java虚拟机识别和运行。
因此,要学习Java字节码(.class)文件的组成,我们先从编译和反编译Java源代码文件开始。
一段Java代码
以下是一段朴实无华的java代码,新建了一个对象,做了个加法运算,仅此而已。
1 | package memoryarea.virtualstack; |
后文将围绕这段Java代码展开,来探索Java字节码藏在0和1背后的秘密。
javac 编译代码
执行 java c 命令:
1 | javac Demo.class |
以上命令可以对Demo.java文件进行编译,编译产生的Demo.class文件是Java字节码文件,可以被JVM识别且执行的文件,编译结果如下(Demo.class文件):
1 | CAFEBABE 00000034 00230A00 02000307 00040C00 05000601 00106A61 |
上面就是Demo.java文件使用javac编译后得到的Demo.class文件的真实内容,实际上Demo.class文件是一个二进制文件,这里我们使用16进制的格式进行展示的。直接看这个文件人类是无法知道有什么用处的,因此我们需要进一步对这个文件进行反编译。
javap -v 反编译代码
执行javap -v命令:
1 | javap -v Demo.class |
执行Java的反编译命令可以讲Java的.class文件反编译成人类可阅读的内容如下:
1 | Classfile /Users/leiqinghua/src/BingGo/JavaDemo/target/classes/memoryarea/virtualstack/Demo.class |
IDEA插件jclasslib
除了使用javap -v 命令之外,也可以借助IDEA插件来查看java的.class文件,来了解Java的字节码文件的构成。执行这个插件之前首先需要安装jclasslib,然后java代码需要手动编译(运行一次),因为其本质上还是分析的Demo.class文件。
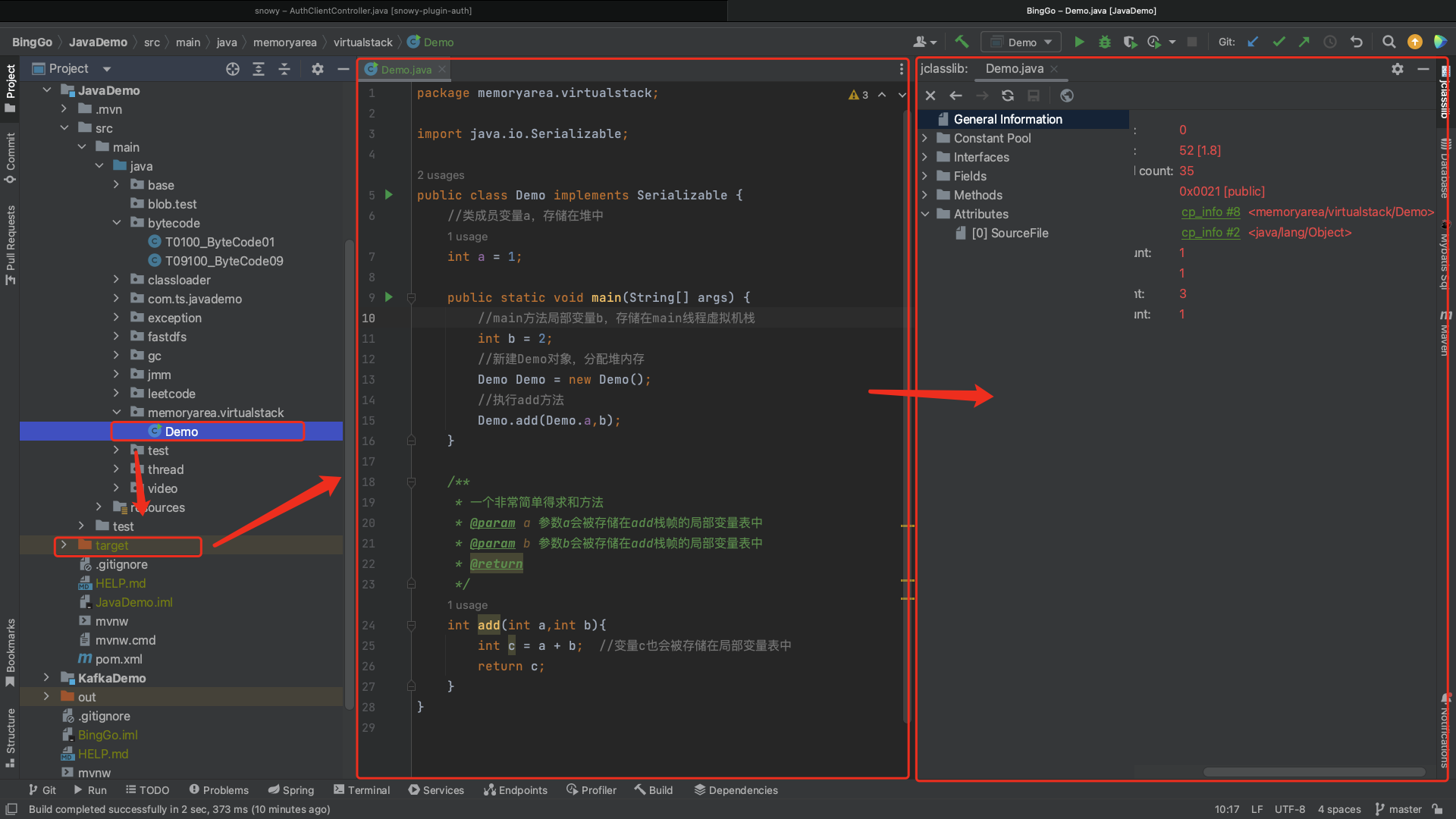
“jclasslib” 是一个 Java 字节码查看和编辑工具,是一个用于 IntelliJ IDEA 的插件。它允许你查看和编辑 Java 类文件的字节码。以下是有关 jclasslib 插件的一些信息:
功能: jclasslib 允许你以可视化的方式查看和编辑 Java 类的字节码。你可以查看类的常量池、方法、字段等,并在需要时进行编辑。这对于理解 Java 字节码的工作原理以及进行一些调试和优化非常有用。
使用: 安装 jclasslib 插件后,你可以在 IntelliJ IDEA 的界面中访问 jclasslib 的功能。通常,你可以在编辑 Java 文件时右键单击类文件,然后选择 jclasslib 的选项以打开字节码查看器。
安装: 你可以通过 IntelliJ IDEA 的插件市场直接搜索 jclasslib 并安装。在 IntelliJ IDEA 中,选择 “File” > “Settings” > “Plugins”,然后搜索 jclasslib 进行安装。
.Class文件格式
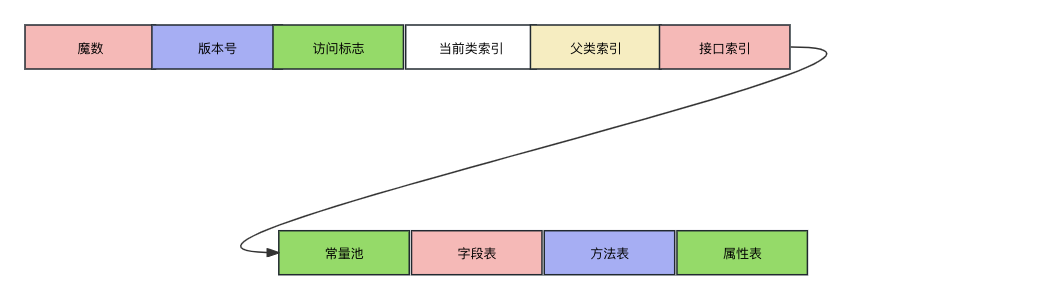
Java 的 .class 文件是一种二进制文件,其中包含 Java 源代码编译后的字节码。以下是 Java .class 文件的主要结构:
- 魔数(Magic Number): 文件的前四个字节是一个魔数,用于标识文件格式。对于 Java .class 文件,魔数的值为
0xCAFEBABE。 - 版本信息: 紧接着魔数的四个字节是 Java 版本信息,包括主版本号和次版本号。
- 常量池(Constant Pool): 常量池紧随版本信息,用于存储字符串、类名、方法名等常量。常量池中的项目数量由两个字节表示,后面是常量池中的各个项目。
- 访问标志(Access Flags): 接着常量池的是类或接口的访问标志,它表示该类或接口的访问级别和特性。
- 类索引、父类索引、接口索引: 这些字段指向常量池中类、父类、接口的描述符。
- 字段表(Fields): 描述类或接口中的字段。包括字段的访问标志、名称索引、描述符索引等。
- 方法表(Methods): 描述类或接口中的方法。包括方法的访问标志、名称索引、描述符索引、属性表等。
- 属性表(Attributes): 用于存储有关类、字段或方法的其他信息。例如,源代码文件名、行号信息等。
对于以上属性的顺序无需太纠结,只需要知道所有的class文件都包含以上内容即可
一般信息
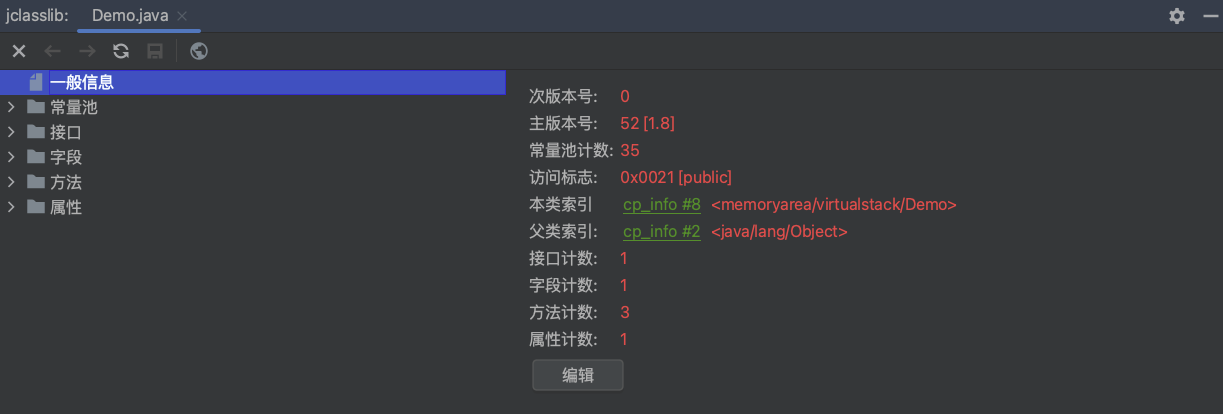
一般信息包括魔数,即0xCAFEBABE,主版本信息,次版本信息,常量池计数,本类索引,父类索引,接口
计数,字段计数,方法计数和属性计数,如下:
- 魔数(Magic Number,4 Bytes): 以
0xCAFEBABE开头的四个字节。 - 主版本号和次版本号(4 Bytes): 表示 Java 编译器的版本。
- 访问标志:描述该class是类还是接口,以及是被public、final等啥修饰符修饰的,对应的就是:
- 常量池计数: 常量池的项目数量。
- 本类索引和父类索引: 分别指向当前类和其父类在常量池中的索引。
- 接口计数和接口索引: 指示类实现的接口数量和接口在常量池中的索引。
- 字段计数: 描述类中的字段信息,包括访问标志、名称索引、描述符索引等。
- 方法计数: 描述类中的方法信息,包括访问标志、名称索引、描述符索引、属性表等。
- 属性计数: 描述类、字段或方法的附加信息,比如源文件名、行号信息等。
常量池
什么是常量池?
Java常量池一般分为两类——静态常量池和运行时常量池。
静态常量池是在Java代码编译期就能够确定的常量,这部分常量通过常量池的方式记录在Java的字节码文件中,等到Java类加载到内存中之后常量池也会被加载到“方法区“。
运行时常亮池可以指当Java的字节码文件被加载到内存之后由静态常量池得到的常量池,也可以是用诸如String.intern()等方法动态添加的常量。
我们这里说的主要是静态常量池,而在JVM的运行时内存区域中所提到的常量池一般是运行时常量池。简单的可以理解为“运行时常量池”就是被加载到内存当中的“静态常量池”。
静态常量池
在Java的Class文件结构中,最开始的4个字节用于存储魔数(Magic Number),其数值为**0xCAFEBABE,用于确认一个文件是否能够被Java虚拟机接受。接着的4个字节用于存储版本号,前2个字节存储次版本号,后2个存储主版本号。紧接着是用于存放常量的常量池,由于常量的数量是不固定的,因此常量池的入口处有一个U2类型的数据(constant_pool_count**)存储常量池的容量计数值。
这部分常量池被称为静态常量池,静态常量池一般是.class文件的一部分,JVM编译器会在编译器将字面量和符号引用存储在常量池中,作为class文件的一部分。静态常量池一般在类的编译期就已经存在,主要包含编译期就确定的“字面量”和“符号引用”。
而运行时常量池(Runtime Constant Pool)是在类加载后,类被解析和初始化时动态生成的一部分内存,用于存储一些在运行期间需要解析的常量信息,它是方法区的一部分。Java代码在运行时,一些常量可能需要在运行期动态生成,例如通过反射、动态代理等机制产生的常量。运行时常量池的内容可以随着程序的执行而动态地变化。运行时常量池的内容可以通过反射等手段动态地进行操作和修改。例如,通过**String.intern()**方法可以将字符串对象加入到运行时常量池中,以便共享相同的字符串字面量。
通俗的解释就是,运行时常量池可以看作是静态常量池在运行时的表示。这两种常量池有很多特性都是一样的主要包括:
- 存储内容: 常量池中主要存储两大类型常量,字面量(Literal)和符号引用。字面量类似于Java中常量的概念,如String字符串、整数、浮点数和被final声明的常量值;符号引用则包括:类和接口的全限定名、字段和方法的名称和描述符等。
- 索引从1开始: 常量池中的项目编号从1开始。这是因为在 Java 编程语言中,数组的索引是从0开始的,而常量池的索引在字节码中以1为起始。
- 共享: 常量池中的字面量和符号引用可以被多个地方引用,从而实现了共享。这有助于减小字节码文件的体积,同时在运行时减少内存的占用。
- 动态性: Java 常量池不仅包含编译期生成的常量,还可以在运行时动态生成常量。这是通过
ldc指令实现的。 - 常量池中的项目类型: 常量池中的项目主要包括类引用、字段引用、方法引用、接口方法引用、字符串字面量、整数和浮点数字面量等。
- 字节码中的指令: 在字节码中,通过常量池中的索引来引用常量。比如,
ldc指令用于将常量池中的常量入栈。
运行时常量池
我们知道Java类执行的时候是需要被加载到内存中的,一个Java类被加载到内存中之后会对应一个运行时常量池。运行时常量池是在类加载的解析阶段生成的,它将类文件常量池中的符号引用替换为直接引用,并保存在方法区中,我们通常说的常量池指的就是方法区中的运行时常量池,这个过程发生在类加载的解析阶段。
与静态常量池相比,运行时常量池具有动态性,静态量池是一个静态存储结构,其中的引用都是符号引用。而运行时常量池在运行期间可以将符号引用解析为直接引用。因此,运行时常量池用于索引和查找字段、方法名称以及描述符。通过给定一个方法或字段的索引,可以最终获取到该方法或字段所属的类型信息,以及名称和描述符信息。这涉及到方法的调用和字段的获取。
Java语言并不要求常量只能在编译期生成,也就是并非只有在类文件常量池中预置的内容才能进入方法区的运行时常量池。在运行期间,新的常量也可能被动态添加到常量池中。String类的intern()方法就是一个典型的例子,String的intern()方法会在常量池中查找是否存在一个与之相等的字符串,如果找到则返回该字符串的引用,否则将自身的字符串添加到常量池中。
通俗的解释就是,运行时常量池可以看作是类文件常量池在运行时的表示。另外,方法区本身是一个逻辑性的区域。在JDK7及之前,HotSpot使用永久代来实现方法区,这种实现完全符合逻辑概念;但在JDK8及以后,永久代被移除,引入了元空间(Metaspace),方法区的实现变得更加分散。元空间仅存储类和类加载器的元数据信息,而符号引用存储在native heap中,字符串常量和静态类型变量存储在普通堆区。在这种情况下,方法区只是对逻辑概念的一种表述。
静态常量池结构
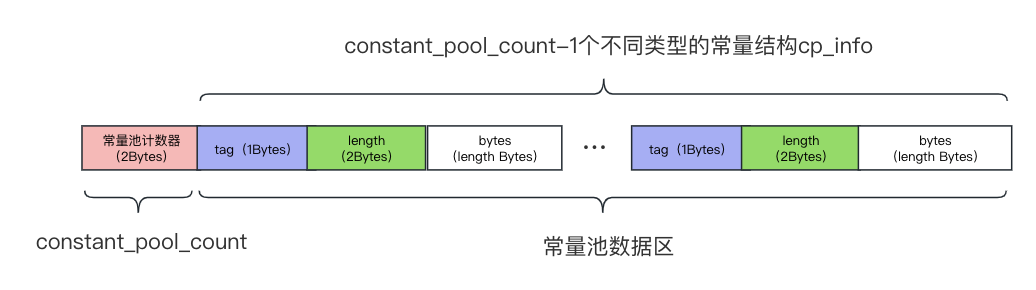
如上图所示,常量池中的每一项常量都是一个表,共有17种不同类型的表项。常量池的结构一般分为2个部分,即:“常量池计数器” 和 “常量池数据区”。常量池计数器就是表示常量池中的元素个数,即多少个表项。而数据区域则类似于一个一个的记录,这些记录由三个部分组成:tag、length和bytes。
其中tag是一个u1类型的标志位,常用于区分常量的类型,如整形、浮点型、String类型和方法类型等。length则是该类型的常量所占的bytes数。bytes则是真实的常量数据部分,这些常量类型的具体含义如下表所示:
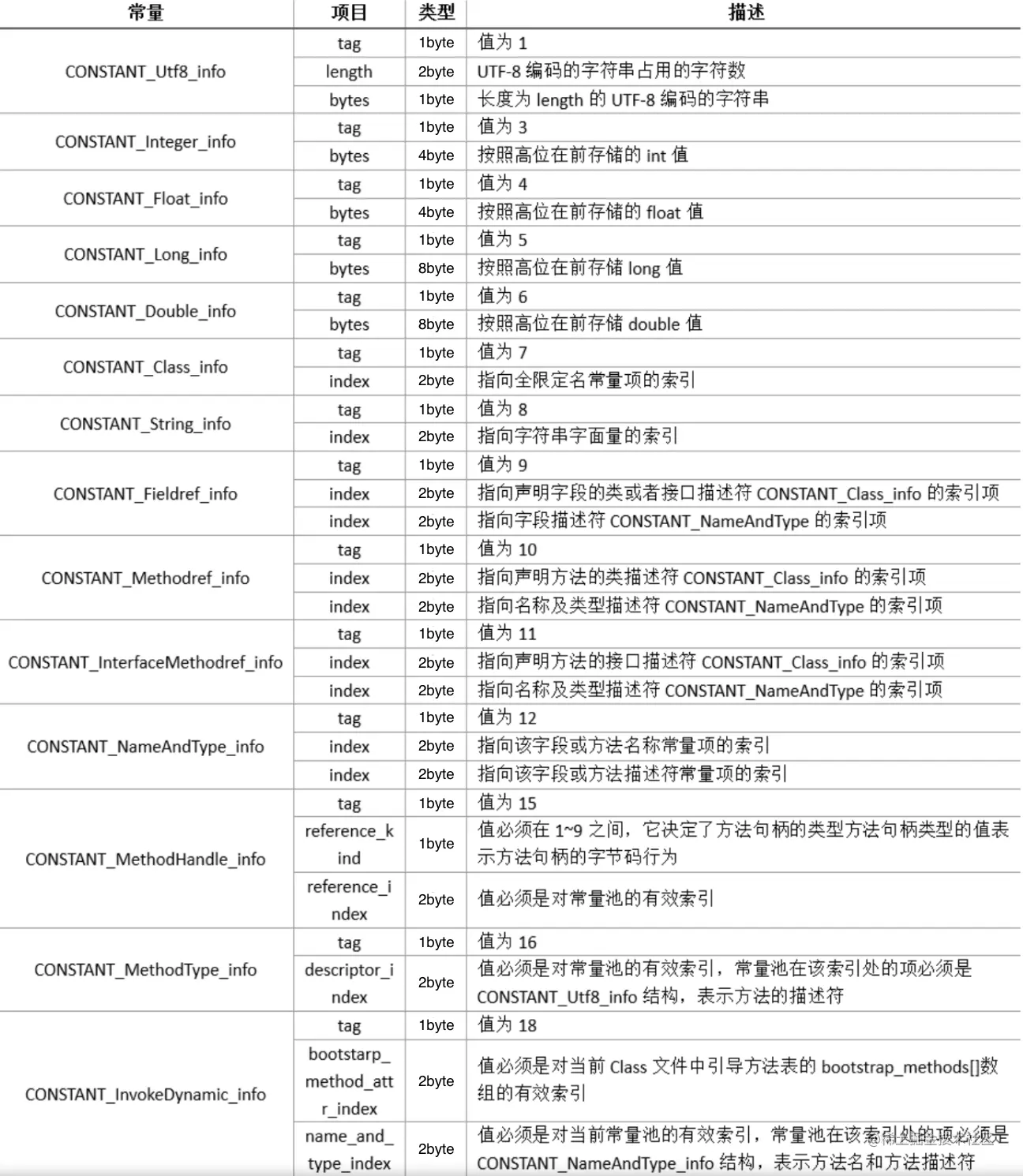
这些类型是 Java 常量池中常见的项目类型,在实际的字节码文件中,常量池中的每个项目都有其特定的格式和结构,以适应不同的引用和字面值。这些内容看起来十分难懂,接下来我们就尝试着分析一下之前代码中的常量池,帮助我们更深刻的理解这部分内容。
常量池示例
1 | Constant pool: |
接下来我们一个个的分析上面常量池中的内容的含义,不感兴趣的可以跳过这部分。
1 | #1 = Methodref #2.#3 // java/lang/Object."<init>":()V |
这里的类型是MethodRef,从上面的表中可以知道这是方法的符号引用,其前2个字节指向“声明方法的类描述符”的索引,即:#2 ;而后2个字节则是“名称”以及“类型描述符“的索引,即:#3。接下来我们看看[#2和#3是代表什么。]
1 | #2 = Class #4 // java/lang/Object |
#2 的类型是Class,该类型指向全限定名常量项的索引,其值为# 4,而# 4则是一个Utf8类型的字符串,表示的是java/lang/Object类型。
#3 的类型是NameAndType,从上表可知其前2个字节只想该字段活着方法名称常量项的索引,后2个字节指向该字段或者方法描述符常量项的索引,即名称和描述符。分别对应# 5和# 6,如下:
1 | #5 = Utf8 <init> |
这个方法是
| 类型 | 值域 | 默认值 | 虚拟机内部符号 |
|---|---|---|---|
| boolean | {false, true} | false | Z |
| byte | [-128, 127] | \u0000 | B |
| short | [-32768, 32767] | 0L | S |
| char | [0, 65535] | \u0000 | C |
| int | [-2^31, 2^31-1] | 0 | I |
| long | [-2^63, 2^63-1] | 0L | J |
| float | [-3.4E38, 3.4E38] | +0.0F | F |
| double | [-1.8E308, 1.8E308] | +0.0D | D |
常量池优势
在Java中,常量池是一种用于存储编译期间生成的字面量和符号引用的特殊内存区域。常量池的存在有以下主要原因:
- 节省空间: Java源文件在编译后生成字节码文件,其中包含了大量的字面量(如字符串、数字、符号)以及对这些字面量的符号引用。直接将这些数据存储在字节码文件中会导致文件庞大,而通过常量池,可以将重复的字面量合并,节省存储空间。
- 提高效率: 常量池中存储了编译期生成的各种字面量和符号引用,包括类名、方法名、参数类型等。在运行时,虚拟机指令可以通过常量池中的引用快速定位和访问这些信息,从而提高代码执行的效率。
- 支持动态链接: 在Java中,类的解析和连接是在运行时进行的,而不是在编译时。在动态链接的过程中,运行时常量池扮演了重要角色,可以支持类、方法、字段等的动态查找和绑定。
- 支持多语言特性: Java虚拟机支持多语言,而不同的语言可能具有不同的数据类型和结构。常量池提供了一种通用的机制,可以存储和管理各种语言中的字面量和符号引用。
- 支持反射和动态代理: 常量池中存储了类的结构信息,包括方法名、字段名等。这些信息对于Java中的反射和动态代理等特性至关重要,使得程序能够在运行时动态地获取和操作类的信息。
综上所述,常量池在Java中具有重要作用,不仅能够节省存储空间,提高代码执行效率,还支持动态链接、多语言特性以及反射等高级特性,使得Java成为一种灵活且功能丰富的编程语言。
接口表
在Java字节码文件中,接口表用于记录一个类实现的接口信息。每个类都可以实现一个或多个接口,而接口表中的每一项都表示类实现的一个接口。
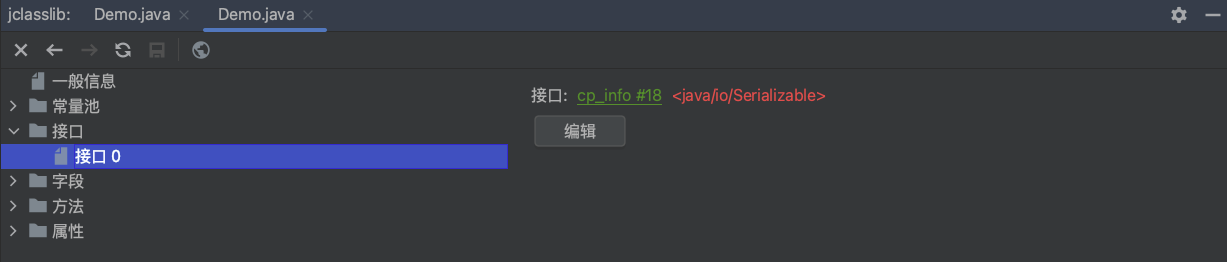
接口信息存储在常量池(constant pool)中,并在类的属性表中有一个interfaces项来表示该类实现的接口。接口在Java字节码中并不包含具体的实现,而只是定义了接口中的方法签名:
- 常量池(constant pool):包含对接口的符号引用。接口的符号引用指向常量池中的一些项,如类的符号引用。
- 类的属性表:在类的属性表中,有一个
interfaces项,用于表示该类实现的接口。这个项包含一个指向常量池中接口的符号引用的索引。
1 | Classfile /Users/leiqinghua/src/BingGo/JavaDemo/target/classes/memoryarea/virtualstack/Demo.class |
在我们的示例代码中,Demo 类实现了一个接口 java.io.Serializable,接口信息和符号引用等细节可以在.class文件的常量池中找到,即#18 和 #20。
字段表
在Java字节码文件中,字段表用于存储类中的字段(成员变量)的信息。每个字段都在字段表中有一项,包含有关该字段的各种信息,例如字段的名称、类型、访问标志等。
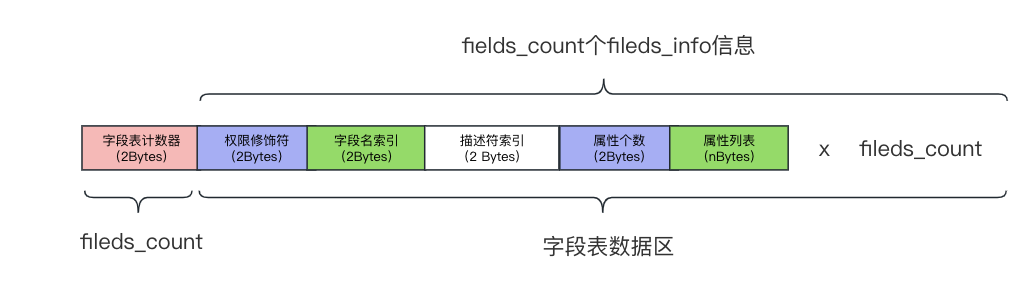
使用jclasslib查看字段表的结果如下:
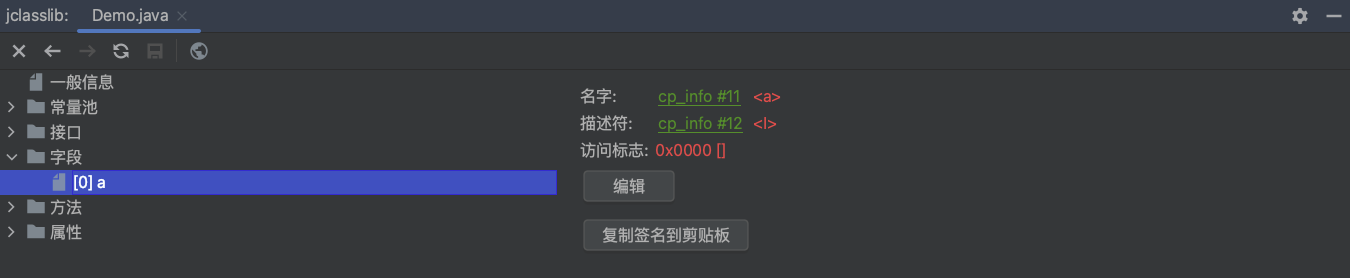
字段表的字节码如下:
1 | int a; |
解释下上面内容:
字段类型:
int,表示字段的数据类型为整型。描述符:
descriptor: I,表示字段的描述符,其中I是整型的标识符。在Java字节码中,I是整型的描述符,用于标识字段的数据类型。访问标志:
flags:在这里没有具体的访问标志。访问标志用于表示字段的可见性和其他属性,例如public、private、static等。在这里可能是因为没有显示指定访问标志,或者它可能是使用默认访问修饰符。
这段代码表示一个整型字段 a,它的类型为整型(int),并且在Java字节码中被表示为 I。
方法表
Java字节码接下来的部分就是方法表部分,方法表是用于存储类中方法信息的数据结构。每个方法都在方法表中有一项,其中包含有关该方法的各种信息,例如方法的名称、返回类型、参数列表、访问标志等。
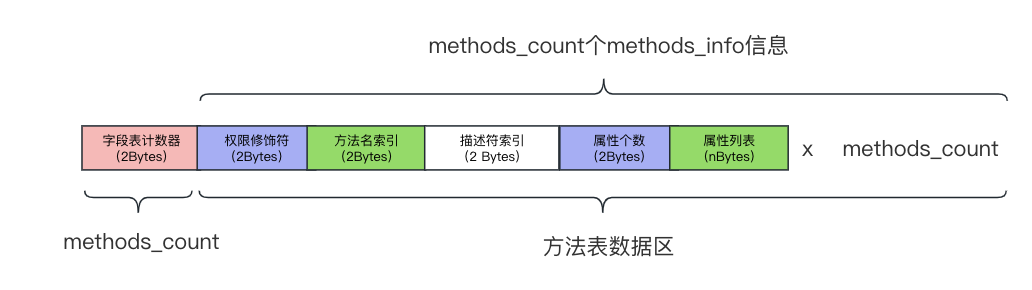
使用jclasslib查看上面示例代码中的方法表的内容如下:
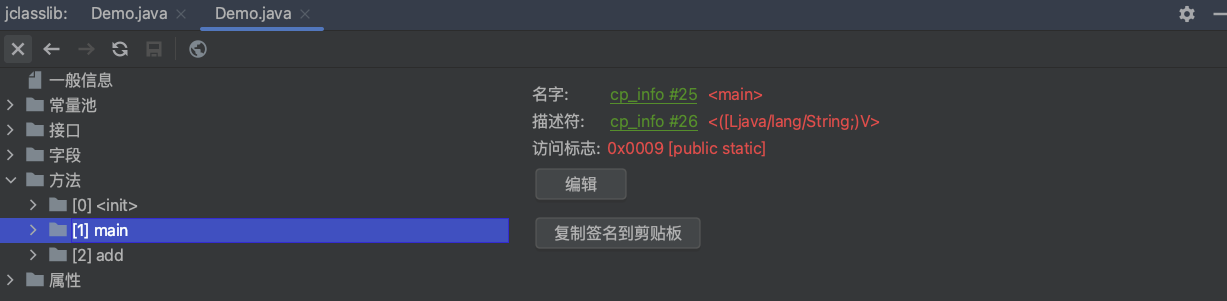
main方法解释
1 | public static void main(java.lang.String[]); //表示这是一个main方法,接受一个String数组作为参数,返回类型为void。 |
这段代码是 main 方法的字节码表示,以下是对其的解释:
- 方法声明:
public static void main(java.lang.String[]);表示这是一个main方法,接受一个String数组作为参数,返回类型为void。 - 方法描述符:
descriptor: ([Ljava/lang/String;)V描述了方法的参数和返回值类型。([Ljava/lang/String;)表示一个String数组,V表示返回类型为void。 - 方法修饰符:
flags: ACC_PUBLIC, ACC_STATIC表示该方法是公共的(public)且是静态的(static)。 - Code 部分: 是方法的字节码实现。
stack=3: 表示操作数栈的最大深度为 3。locals=3: 表示局部变量表的最大容量为 3。args_size=1: 表示方法参数的个数为 1。
- 字节码指令:
iconst_2: 将常量 2 推送到栈顶。istore_1: 将栈顶元素存储到局部变量表索引为 1 的位置。new <span data-type="tag" data-tag-lazy-create-name="3“> 创建一个新的Demo对象。dup: 复制栈顶数值并将复制值压入栈顶。invokespecial <span data-type="tag" data-tag-lazy-create-name="4:”> 调用Demo对象的构造函数。astore_2: 将Demo对象引用存储到局部变量表索引为 2 的位置。aload_2: 将Demo对象引用加载到栈顶。aload_2: 再次加载Demo对象引用。getfield <span data-type="tag" data-tag-lazy-create-name="2:”> 获取Demo对象字段a的值。iload_1: 将整数常量 2 加载到栈顶。invokevirtual <span data-type="tag" data-tag-lazy-create-name="5:”> 调用Demo对象的add方法。pop: 弹出栈顶数值。return: 返回。
- LineNumberTable:
line 9: 0: 表示源代码的第 9 行对应字节码的第 0 个指令。line 11: 2: 表示源代码的第 11 行对应字节码的第 2 个指令。line 13: 10: 表示源代码的第 13 行对应字节码的第 10 个指令。line 14: 20: 表示源代码的第 14 行对应字节码的第 20 个指令。
这段代码的主要作用是在 main 方法中创建一个 Demo 对象,调用其 add 方法,并在最后返回。
构造方法解释
1 | public memoryarea.virtualstack.Demo(); |
这段代码是 Demo 类的构造函数(无参构造方法)的字节码表示,以下是对其的解释:
- 方法声明:
public memoryarea.virtualstack.Demo();表示这是一个公共的无参构造方法。 - 方法描述符:
descriptor: ()V描述了方法的参数和返回值类型。()表示没有参数,V表示返回类型为void。 - 方法修饰符:
flags: ACC_PUBLIC表示该方法是公共的(public)。 - Code 部分: 是方法的字节码实现。
stack=2: 表示操作数栈的最大深度为 2。locals=1: 表示局部变量表的最大容量为 1。args_size=1: 表示方法参数的个数为 1。
- 字节码指令:
aload_0: 将当前对象引用加载到栈顶。invokespecial <span data-type="tag" data-tag-lazy-create-name="1:”> 调用java/lang/Object类的无参构造方法(超类构造方法)。aload_0: 再次将当前对象引用加载到栈顶。iconst_1: 将整数常量 1 推送到栈顶。putfield <span data-type="tag" data-tag-lazy-create-name="2:”> 将栈顶的值(整数常量 1)存储到对象的字段a中。return: 返回。
- LineNumberTable:
line 3: 0: 表示源代码的第 3 行对应字节码的第 0 个指令。line 5: 4: 表示源代码的第 5 行对应字节码的第 4 个指令。
这段代码的主要作用是初始化 Demo 类的实例。在构造函数中,首先调用超类(java/lang/Object)的构造函数,然后将字段 a 的值设置为整数常量 1。
add(int a,int b)方法解释
1 | int add(int, int); //表示这是一个返回类型为int的方法,方法名为add,接受两个int类型的参数。 |
这段代码实现了一个简单的加法函数,将两个参数相加并返回结果。在字节码中,参数通过iload_1和iload_2加载到操作数栈,相加后通过istore_3存储到局部变量表,然后再次加载到操作数栈并通过ireturn返回。
这段代码是一个简单的 Java 方法的字节码表示,以下是对其的解释:
- 方法声明:
int add(int, int);表示这是一个返回类型为 int 的方法,方法名为 add,接受两个 int 类型的参数。 - 方法描述符:
descriptor: (II)I描述了方法的参数和返回值类型。(II)表示两个 int 类型的参数,I表示返回类型为 int。 - Code 部分: 是方法的字节码实现。
stack=2: 表示操作数栈的最大深度为 2。locals=4: 表示局部变量表的最大容量为 4。args_size=3: 表示方法参数的个数为 3。
- 字节码指令:
iload_1: 将局部变量表第一个参数加载到操作数栈。iload_2: 将局部变量表第二个参数加载到操作数栈。iadd: 执行整数相加。istore_3: 将结果存储到局部变量表索引为 3 的位置。iload_3: 将之前存储的结果加载到操作数栈。ireturn: 返回整数值。
- LineNumberTable:
line 23: 0: 表示源代码的第 23 行对应字节码的第 0 个指令。line 24: 4: 表示源代码的第 24 行对应字节码的第 4 个指令。
在字节码中,通过 iload_1 和 iload_2 指令将两个参数加载到操作数栈,然后通过 iadd 进行整数相加,将结果通过 istore_3 存储到局部变量表,最后通过 iload_3 将结果加载到操作数栈,并通过 ireturn 返回整数值。LineNumberTable 提供了源代码行号与字节码指令的映射,有助于调试时定位源代码位置。
属性表
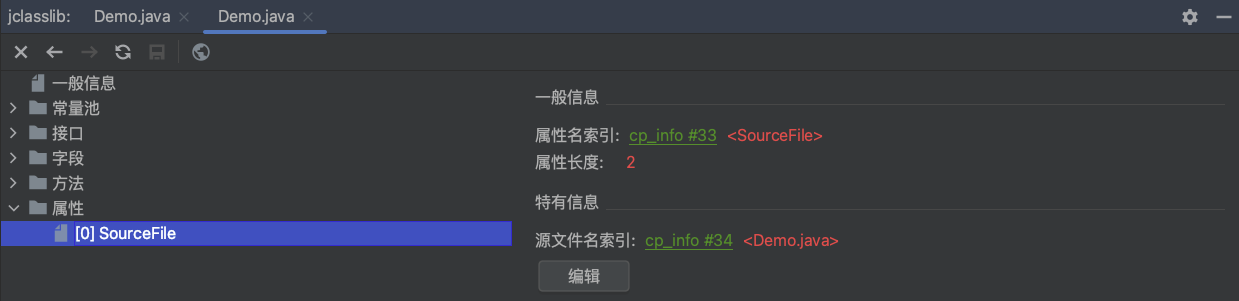
在Java字节码文件中,属性部分提供了有关类或方法的附加信息。每个属性都由两个部分组成:属性名称索引和属性信息。以下是常见的一些属性:
| 属性 | 属性信息 | 说明 |
|---|---|---|
| SourceFile | 例如:”Demo.java” | 表示源文件的名称为 “Demo.java” |
| Code | 包含方法的实际字节码指令、异常处理表、局部变量表等。 | 存储方法体的字节码指令,执行方法的实际代码 |
| LineNumberTable | 包含源代码行号和字节码行号的映射关系。 | 在调试时将字节码行号映射回源代码行号 |
| LocalVariableTable | 包含方法的局部变量名称、类型、作用域等信息。 | 在调试时显示局部变量的信息 |
| MethodParameters | 包含方法参数的名称和访问标志。 | 在调试时获取方法参数的名称 |
这里只列举了一些常见的属性,实际上,Java字节码文件可能包含其他属性,具体取决于编译器和使用的工具。每个属性的具体信息格式在Java虚拟机规范中有详细描述。
总结
这段 Java 代码通过编译生成了字节码文件 Demo.class,然后使用了jclasslib等工具来介绍了Java字节码文件的组成。Java的字节码文件(.class)文件是一个二进制文件,是JVM执行的文件,一般由:一般信息、常量池、接口信息、字段表、方法表、属性表等几个部分构成。
其中最为重要的是常量池部分,分为静态常量池和运行时常量池,主要是将Java方法中所定义的“字面量”和“符号引用”统一管理了起来,方便JVM进行相关常量的复用。逻辑上来说,在Java类被加载的时候,常量池一般存储在“方法区”当中,在类加载的解析过程中还会根据常量池将类中的符号引用替换成实际的物理地址引用。
我们的JVM在运行的时候就是逐行的将这些字节码翻译成不同平台的汇编代码和机器码在不同的平台上运行的,所以说,Java字节码文件的构成实际上是使用JVM所有语言学习的一个基础。
-
免责声明
- 本文发布的信息,最终解释权归作者所有,如有疑问或需要进一步了解,请直接与作者联系。
- 本文部分信息来源于网络,其版权归原作者所有,本文使用该信息仅出于分享给求职者,无任何商业用途,如有侵权,请联系作者删除。
- 本文发布的信息旨在为应届生和社会人士提供了解相关企业招聘信息的便利,不涉及任何机密信息,且所有信息均为网络公开获取。 本人亦无任何渠道可以了解任何机密信息, 如果您认为某些内容存在侵权、泄密问题,请及时联系作者删除。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

更多央国企信息、面试辅导、简历修改等,请关注知识星球:[成都央国企指南]